Performance testing should be an asset pipeline, not a one-off run
A product-operations view of AI-Locust: the framework matters because it turns benchmark execution into durable, reviewable, repeatable assets.
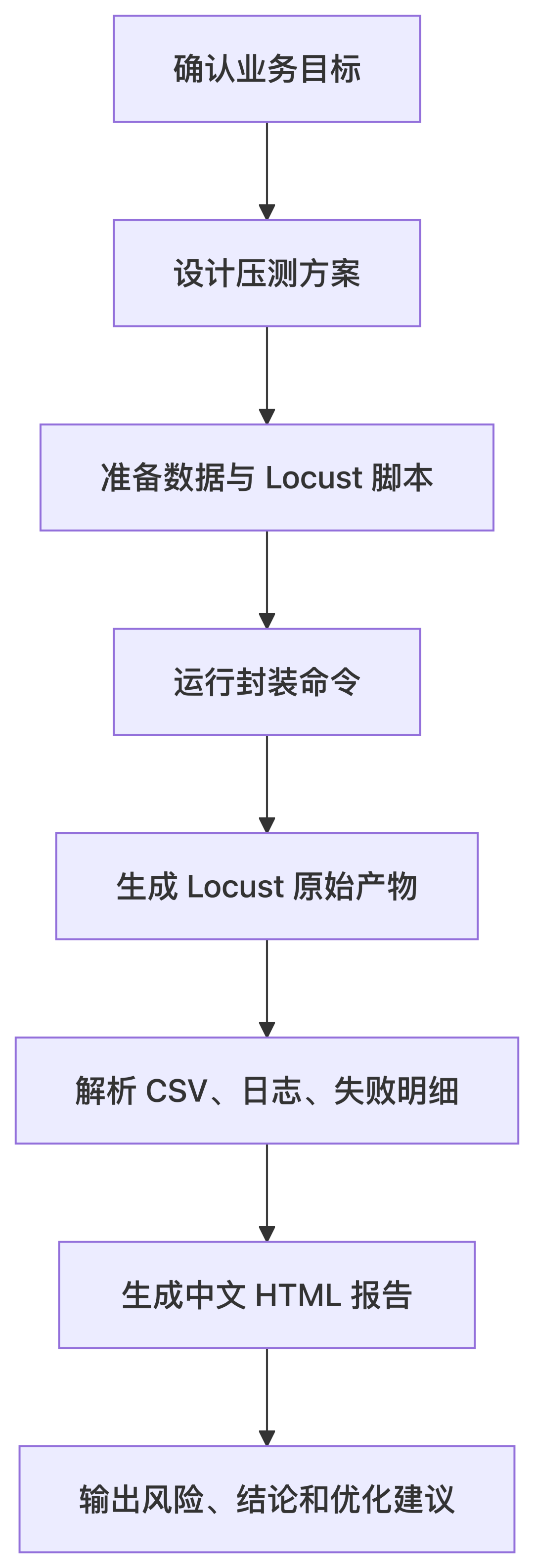
From an operations standpoint, the real value of AI-Locust is not the test run itself. It is the fact that every run leaves behind the pieces a team needs to operate performance work like a process: plan, execution, evidence, and conclusion.
Why this is an operations problem
A load test that cannot be replayed or compared is basically a throwaway. When scripts live in one place, data in another, and conclusions in chat, nobody owns the lifecycle. AI-Locust makes that lifecycle explicit.
The framework’s folder structure is the real product decision: raw results go one place, final HTML reports another, and analysis artifacts another. That means a team can track changes, review past baselines, and reuse the same process for the next release.
What teams should care about
- Can a non-author recreate the run later?
- Are thresholds defined before the test starts?
- Is failure analysis backed by raw logs and CSVs?
- Can the report stand alone for engineering review?
In practice, this is where many performance-testing efforts fail: they produce numbers, but not operating memory. AI-Locust is valuable because it forces memory into the structure of the work.
How to adopt it safely
- Start with one endpoint and one baseline test.
- Keep the raw report and the final report separate.
- Use AI for narrative, but keep the CSVs as the source of truth.
- Track repeated failures as process debt, not as one-off noise.
If a team treats performance testing like an operational capability, this kind of framework is a good fit. If the team only wants a quick number for a release meeting, it is overkill.